生成模型基础 | 8 流模型
17 Flow Matching
17.1 CNF revisited
先简单地回顾一下连续归一化流 (CNF). 假设我们想要学习一个很复杂的分布
\(X_1\sim\pi_1\), CNF
的做法是先取一个简单分布 \(X_0\sim\pi_0\) (比如标准正态分布),
再用一个流 \(\Phi:[0,1]\times\R^d\to\R^d\) 将 \(X_0\) “推” 到 \(X_1\), 即希望 \[
\Phi(0,X_0) \sim \pi_0, \qquad
\Phi(1,X_0) \sim \pi_1.
\] 流 \(\Phi(t,x)\)
17.2 Flow matching
流匹配 (flow matching) 的思想是类似的, 仍是用一个神经网络拟合向量场 \(V(t,x)\), 但是它绕过了昂贵的 ODE 模拟, 是一种高效且稳定的方法. FM 的想法很巧妙:
CNF 设计了一个流 \(\Phi\), 让 “一团噪声” \(\pi_0\) 一下子变成 “一团数据” \(\pi_1\), 如下图左. 这么做很困难, 因为这是高度一个欠定的问题 (真实分布 \(\pi_1\) 未知).
将视角从宏观转向微观, 我们从 \(\pi_0\) 和 \(\pi_1\) 分别采样 \(x_0,x_1\), 然后根据特定规则 (比如线性插值) 构造一条路径 \(I:[0,1]\to\R^d\) 把两者连起来, 如下图中.
路径 \(I\) 上的每个点 \(x_t\) 都有切向量 \(\partial_t I_t\), 我们让神经网络 \(v_\theta(x,t)\) 拟合切向量, 损失函数为 MSE \[ \operatorname{E}_t \| v_\theta(I_t,t) - \partial_t I_t \|_2^2. \]
只学习一条路径当然不够, 我们多次采样 \(x_0,x_1\), 然后计算平均损失 \[ \operatorname{E}_{t,x_0,x_1} \| v_\theta(I_t,t) - \partial_t I_t \|_2^2, \] 这样神经网络 \(v_\theta(x,t)\) 就可以学习到 “经过 \(x\) 点的所有路径在 \(x\) 处切向量的平均值” (下图右), 给出将 \(\pi_0\) 推到 \(\pi_1\) 的向量场!
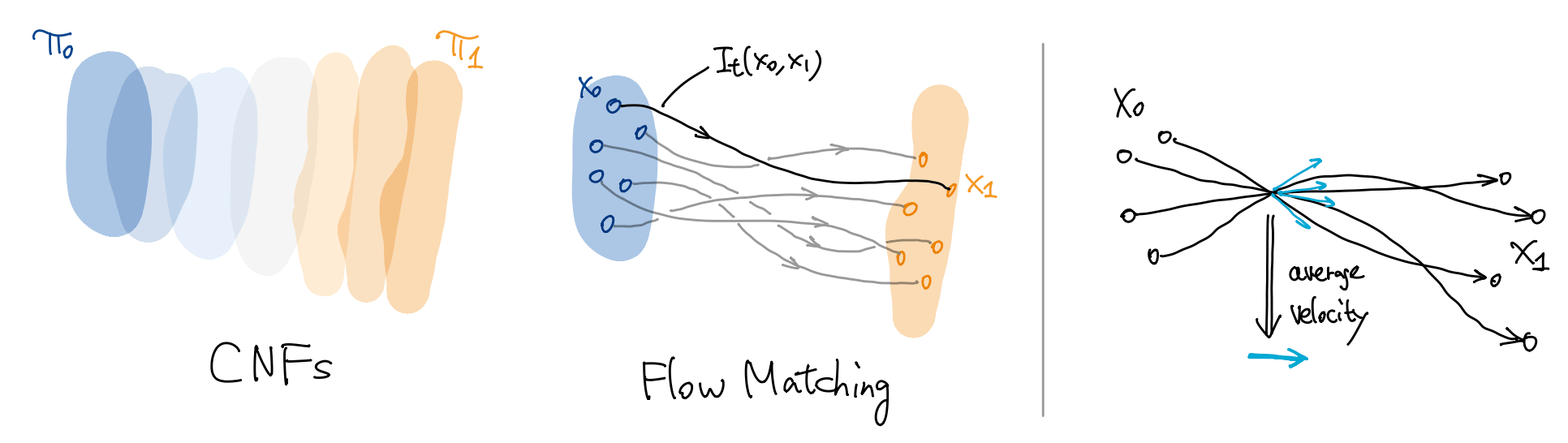
下面给出 FM 的严格叙述. 第一步采样 \(x_0,x_1\) 时, 我们可以独立采样 \(x_0\sim\pi_0\) 和 \(x_1\sim\pi_1\),
但是一种更好的办法是选取一个联合分布 \(\gamma(x_0,x_1)\in\Pi(\pi_0,\pi_1)\)
以 \(x_0,x_1\) 为端点的路径记作 \(I_t(x_0,x_1)\), 也称为插值函数 (interpolant). 最简单的插值函数是线性插值, 即 \(I_t(x_0,x_1)=(1-t)x_0+tx_1\). 插值函数也可以引入随机噪声, 记作 \(I_t(x_0,x_1,z)\), 通常取 \(z\sim\mathcal{N}(0,I)\). 插值函数对时间的导数 \(\partial_t I_t(x_0,x_1,z)\) 就是路径的切向量.
- 插值函数要满足边界条件 \(I_0(x_0,x_1,z)=x_0\) 以及 \(I_1(x_0,x_1,z)=x_1\). 噪声 \(z\) 在路径中淡入淡出, 目的通常是把路径 “吹厚”.
FM 的损失函数可以写作 \[ \mathcal{L}(\theta) = \operatorname{E}_t \operatorname{E}_{(x_0,x_1)\sim\gamma} \operatorname{E}_z \Bigl\| v_\theta\bigl( I_t(x_0,x_1,z),t \bigr) - \partial_t I_t(x_0,x_1,z) \big|_t \Bigr\|_2^2. \] 这可以看作一个速度场的回归问题, FM 的巧妙之处在于把一个生成任务转化为了回归任务. Ground truth 速度 \(\partial_t I_t(x_0,x_1,z)|_t\) 是我们人工构造出来, 也叫做 velocity label. 注意对于同一个点 \(I_t(x_0,x_1,z)\in\R^d\), 可能有很多不同的 labels \(\partial_t I_t(x_0,x_1,z)|_t\) (不同的路径穿过同一点).
可以证明, 在 MSE 损失下, 神经网络学到的是不同 labels 的条件均值, 即 \[ v_\theta^*(x,t) = \operatorname{E}_{(x_0,x_1)\sim\gamma} \operatorname{E}_z \Bigl[ \partial_t I_t(x_0,x_1,z) \big|_t \Bigm| I_t(x_0,x_1,z)=x \Bigr]. \]
17.3 Variants
下面介绍一些 FM 的具体例子.
Gaussian CFM
- Gaussian CFM 和扩散模型很接近, 它本质上是在学习一条 Gauss 去噪的 PF-ODE. 取特定的 \(\mu_t(x_1)\) 和 \(\sigma_t\), 可以分别得到 VE-SDE 和 VP-SDE 的 PF-ODE 向量场. 所以说, FM 可以看作一种更通用的框架.
Rectified flow
- 优点: 形式简单、实现方便、采样路径更短.
- 缺点: 独立 \(\gamma\) 会制造大量不合理配对, 网络需要平均大量交叉路径, 通常需要 reflow 才能得到很直的采样轨迹.
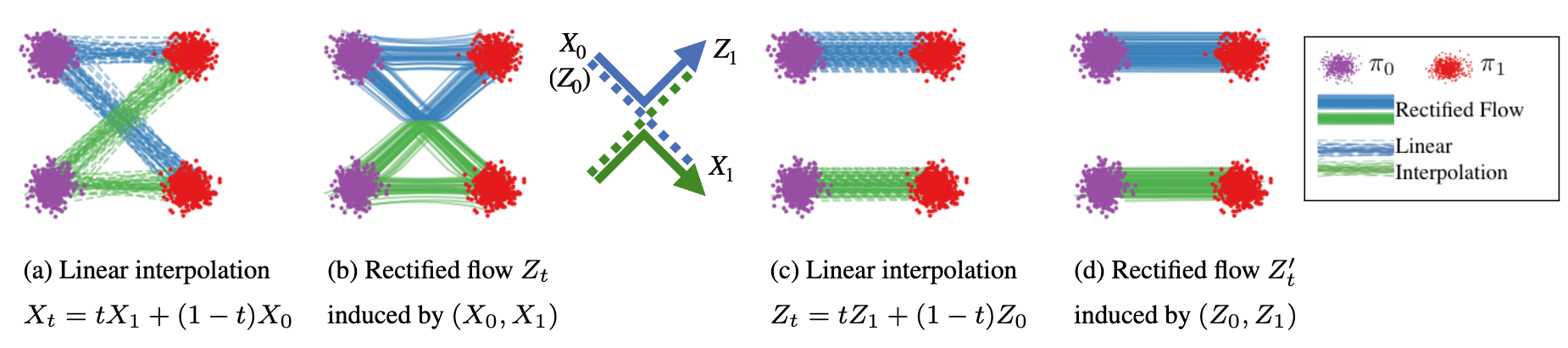
Optimal-transport CFM
- 优点:路径几何更好, 采样步数更少.
- 缺点: 需求解最优传输, 计算成本更高. 实现中通常用 minibatch OT 近似, 质量依赖 batch size 和 cost 设计. 另外, 在高维图像空间中, 欧氏距离不一定是语义合理的最优传输代价函数.
18 *A Geometric View for CNF
CNF 是一个很通用的框架, 给出了将一个分布 \(\pi_0\) 变成另一个分布 \(\pi_1\) 的数学模型. 本章我们用一种更 “几何”
的方式来看 CNF. 我们会略去严谨复杂的证明, 尽量直观地呈现理论脉络
CNF 的核心思想是, 用一个向量场来指导概率分布的演化
- 研究向量场如何推动概率密度 \(\{\rho_t\}_{t\in[0,1]}\) 演化. (Sec. 1)
- 考虑所有概率密度组成的空间, 则 \(\{\rho_t\}_{t\in[0,1]}\) 组成空间中一条曲线, 研究曲线的切向量. (Sec. 2)
- 考虑概率密度空间上的泛函, 其梯度场指导 \(\{\rho_t\}_{t\in[0,1]}\) 演化. (Sec. 3)
- 取几种特殊的泛函, 分别可以得到 VE-SDE, Langevin 和 VP-SDE 过程. (Sec. 4)
18.1 Vector fields
设 \(\R^d\) 上有含时向量场 \(v:[0,1]\times\R^d\to\R^d\), 写作 \(v_t(x)\) (让时间变量作为下标). 向量场 \(v_t\) 生成的流 \(\Phi:[0,1]\times\R^d\to\R^d\) 告诉了空间中每一点 \(x\) 处的粒子如何运动, 即 \[ \dv{t} \Phi_t(x) = v_t(\Phi_t(x)), \qquad \Phi_0(x) = x. \] 设粒子初始分布为 \(\rho_0\), 则粒子在空间中的分布 \(\rho_t:\R^d\to(0,+\infty)\) 也随时间变化, 并且满足连续性方程 (质量守恒): \[ \partial_t\rho_t = -\nabla\cdot(\rho_t v_t). \] 直观地说, \(\partial_t\rho_t(x)\) 表示 \(x\) 处粒子密度的变化率, 速度向量 \(v_t(x)\) 告诉粒子如何移动, 乘积 \(\rho_t(x)v_t(x)\) 表示 \(x\) 处的粒子通量. 连续性方程告诉我们, \(x\) 处粒子密度变化率就等于粒子通量的负散度. (比如, 散度为正代表粒子向四周分散, 恰好对应粒子密度变化率为负.)
18.2 The space of distributions
让理论变得更抽象、更一般的方法是定义新的空间. 考虑 \(\R^d\) 上所有 (存在二阶矩的) 概率密度 \(\rho\) 组成的集合 \(\mathcal{P}_2(\R^d)\). 空间 \(\mathcal{P}_2(\R^d)\) 叫做 \(2\)-Wasserstein 空间, 其中的每个点 \(\rho\) 都是 \(\R^d\) 上的函数, 而空间中的一条曲线 \(t\mapsto\rho_t\) 则给出了连续变化的一族概率密度, 如下图.
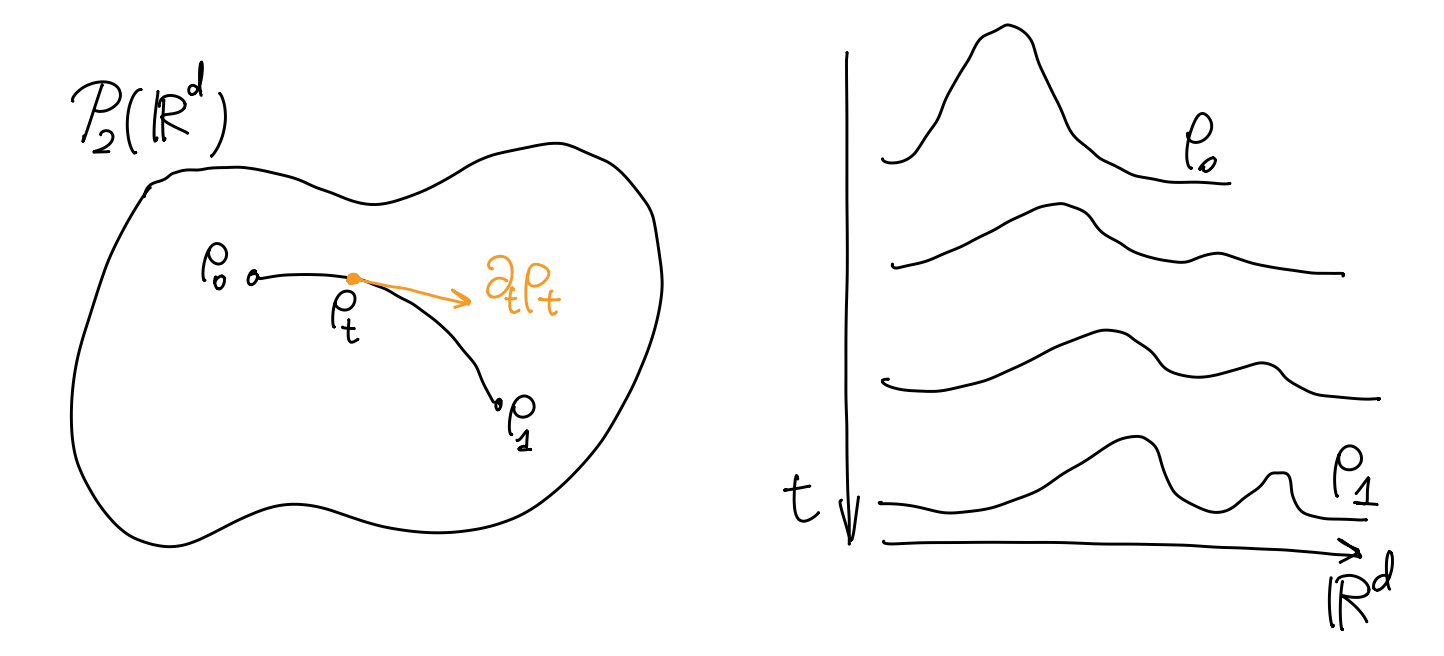
Wasserstein 空间是无穷维的, 即每个点 \(\rho\) 都有无穷多个坐标分量. 坐标可以形式地理解为 \(\{\rho(x)\}_{x\in\R^d}\), 也就是 \(\rho\) 在 \(\R^d\) 中每个点处的取值, 一共 \(\abs{\R^d}\) 这么多个数. 在这个 “坐标系” 下, 曲线 \(t\mapsto\rho_t\) 切向量的分量就是坐标关于 \(t\) 的导数 \(\partial_t\rho_t\). 自然地, 这个切向量是一个无穷维的向量.
现在, 假设曲线 \(t\mapsto\rho_t\) 是
\(\R^d\) 上的某个含时向量场 \(v_t\) 的流生成的, 那么, 连续性方程告诉我们,
这条曲线在 \(t\) 时刻的切向量 \(\partial_t\rho_t\) 恰好等于 \(-\nabla\cdot(\rho_tv_t)\). 因此,
Wasserstein 空间的切向量与 \(\R^d\)
上的速度场几乎是同一个东西
Note 为什么要考虑所有概率密度 \(\rho\) 构成的空间, 并研究曲线 \(t\mapsto\rho_t\) 的切向量? 可以用 ML 中经典的梯度下降法做一个类比.
设神经网络 \(f_\theta:\R^m\to\R^n\), 参数 \(\theta\) 所有可能的值组成参数空间 \(\Theta\). 在梯度下降法中, 我们定义了一个损失函数 \(\mathcal{L}:\Theta\to\R\), 并从一个初始值 \(\theta_0\in\Theta\) 开始, 不断地沿着 \(\mathcal{L}\) 的负梯度方向前进, 最终走到 \(\mathcal{L}\) 的极小值点.
在这个过程中, 参数 \(\theta\)
走过的路径组成了 \(\Theta\)
中的一条曲线
回到概率密度的场景. Wasserstein 空间 \(\mathcal{P}_2(\R^d)\) 就好比 \(\Theta\), 只不过前者是无限维的, 后者是有限维的. 概率密度演化曲线 \(t\mapsto\rho_t\) 就好比优化过程曲线 \(t\mapsto\theta_t\). 一个自然的想法是: 既然 \(\Theta\) 上的函数可以指导参数的优化过程, 那么 \(\mathcal{P}_2(\R^d)\) 上是否有类似的构造?
18.3 Gradient flows
设 Wasserstein 空间上的函数 (泛函) \(\mathcal{F}:\mathcal{P}_2(\R^d)\to\R\), 我们的目标是求它的梯度. 在流形上定义梯度需要先构造度量, 并涉及一些计算过程. 这里略去中间过程, 直接给出 \(\mathcal{F}\) 在 \(\rho\) 处的 Wasserstein 梯度为 \[ \nabla_W \mathcal{F}|_\rho = -\nabla\cdot\pqty{ \rho \nabla \frac{\delta \mathcal{F}}{\delta \rho} }, \] 其中 \(\delta\mathcal{F}/\delta\rho\) 为 \(\mathcal{F}\) 的一阶变分, 其本身是 \(\R^d\to\R\) 的光滑函数.
现在我们可以定义 Wasserstein 空间上的梯度流了. 和前面梯度下降一样, 这里我们考虑负梯度. 从一个初始点 \(\rho_0\in\mathcal{P}_2(\R^d)\) 开始, 沿着 \(\mathcal{F}\) 的负梯度前进. 根据梯度的几何意义, 每次前进的方向都是使得 \(\mathcal{F}\) 下降最快的方向. 用曲线 \(t\mapsto\rho_t\) 表示这一过程, 则曲线在 \(t\) 时刻的切向量 \(\partial_t\rho_t\) 就等于 \(\rho_t\) 处的负 Wasserstein 梯度, 即 \[ \partial_t \rho_t = \nabla\cdot \biggl( \rho_t \nabla \eval{\frac{\delta \mathcal{F}}{\delta \rho}}_{\rho_t} \biggr). \] 注意到 \(-\nabla \eval{\frac{\delta \mathcal{F}}{\delta \rho}}_{\rho_t}\) 恰好是 \(\rho_t\) 所对应的速度场 \(v_t\).
18.4 Diffusions and flows
下面给出一些具体的例子.
势能泛函. 给空间 \(\R^d\) 上的每一点赋予一个势能 \(U(x)\), 则密度 \(\rho(x)\) 的势能由一个泛函给出: \[ \mathcal{F}(\rho) = \int_{\R^d} U(x) \rho(x) \dd{x}. \] 于是 \(\delta\mathcal{F}/\delta\rho=U\), 速度场为 \(v_t(x)=-\nabla U(x)\). 这正是粒子系统 \[ \dd{x_t} = -\nabla U(x_t) \dd{t} \] 的密度演化方程. 最终, 所有的粒子都会聚集在 \(U\) 的极小值点, 系统势能泛函 \(\mathcal{F}(\rho)\) 取到极小值.
负熵泛函. 考虑负熵泛函 \[ \mathcal{F}(\rho) = \int_{\R^d} \rho(x) \log\rho(x) \dd{x}, \] 其一阶变分 \(\delta\mathcal{F}/\delta\rho=\log\rho+1\), 所以 Wasserstein 梯度流为 \[ \partial\rho_t = \nabla\cdot(\rho_t\nabla\log\rho_t) = \nabla\cdot(\nabla\rho_t) = \Delta\rho_t, \] 恰好是 \(\R^d\) 上的热方程. 它对应的粒子 SDE 为纯布朗运动 \(\dd{x_t}=\sqrt{2}\dd{w_t}\), 方差随着时间无限制增大, 质量会不断扩散到整个空间. 所以负熵流就是无目的地自由扩散、熵不断增加的过程. 在上一篇扩散模型中提到的 VE-SDE \(\dd{x_t}=\sigma(t)\dd{w_t}\) 可以看作负熵流的时间重参数化, 即不同时间的速度不同.
KL 泛函与 Langevin 动力学. KL
泛函是势能泛函与熵泛函的组合版本. 给定分布 \(\pi(x)=\frac{1}{Z}\exp(-U(x))\), 其中 \(Z\) 为归一化系数. 定义 KL 泛函 \[
\Align{
\mathcal{F}(\rho)
= D_{\textsf{KL}}(\rho\parallel\pi)
&= \int_{\R^d} \rho(x) \log\frac{\rho(x)}{\pi(x)} \dd{x} \\
&= \int_{\R^d} \rho(x) \log\rho(x)\dd{x}
+ \int_{\R^d} \rho(x)U(x)\dd{x}
+ \log{Z},
}
\] 即势能泛函与熵泛函之和. 它的速度场为
Gaussian KL 泛函与 VP-SDE. 特别地, 在 KL 泛函中取势能 \(U(x)=\frac12\|x\|^2\), 也就是平衡分布为标准正态分布 \(\mathcal{N}(0,I)\). 对应的 SDE 为 \[ \dd{x_t} = -x_t \dd{t}{} + \sqrt{2}\dd{w_t}. \] 同负熵流与 VE-SDE 的关系类似, VP-SDE \(\dd{x_t}=-\frac{1}{2}\beta(t)x_t\dd{t}{}+\sqrt{\beta(t)}\dd{w_t}\) 可以看作 Gaussian KL 流的时间重参数化.
关于流模型. VP-SDE 和 VE-SDE 这两种扩散模型都可以从 Wasserstein 梯度流的角度解释, 从这个角度看很符合直觉. 但一般的流模型则不对应 Wasserstein 梯度流. 如果说扩散模型是 \(\mathcal{P}_2(\R^d)\) 上的梯度流诱导了 \(\R^d\) 上的粒子扩散, 那么 FM 则是先设计 \(\R^d\) 中粒子级随机桥, 再观察分布 \(\{\rho_t\}\) 在 \(\mathcal{P}_2(\R^d)\) 中的轨迹. 此时, 曲线 \(t\mapsto\rho_t\) 未必由梯度流给出. 一个有趣的例子是, OT-CFM (最优传输流匹配) 对应的是 Wasserstein 流形 \(\mathcal{P}_2(\R^d)\) 中的测地线, 即给定起点与终点后, 长度最短的曲线.
严格来说, 含时向量场的流应该写作 \(\Phi(t,t_0,x)\), 其中包括初始时间 \(t_0\). 这里由于我们假定 \(t_0=0\) 故略去.↩︎
集合 \(\Pi(\pi_0,\pi_1)\) 中的元素是 \(\R^d\times\R^d\) 上的分布, 并且以 \(\pi_0,\pi_1\) 为边缘分布.↩︎
Lipman et al, Flow Matching for Generative Modeling, ICLR 2023.↩︎
Liu et al, Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, ICLR 2023.↩︎
Alexander Tong et al, Improving and generalizing flow-based generative models with minibatch optimal transport, TMLR 2024.↩︎
更多细节可以参考 Otto calculus 的文献.↩︎
基于得分的模型 (SBM) 和流匹配 (FM) 都是在学习这个向量场.↩︎
严格地说, 给定 \(\partial_t\rho_t\) 时, 满足连续性方程的速度场 \(v_t\) 并不唯一. Wasserstein 几何中通常选取梯度场作为标准代表元. 本文不展开这一点.↩︎
假设迭代步长足够小, 则近似看一条光滑曲线.↩︎
这个速度场与通常意义下的 CNF 略有区别, 因为它依赖密度 \(\rho_t(x)\).↩︎