生成模型基础 | 7 基于 SDE 的模型
这篇文章的主要思想来自于原论文作者 Yang Song (宋飏) 的博客: Generative Modeling by Estimating Gradients of the Data Distribution. 基于 SDE 的生成模型是一个很通用的框架, 许多模型都可以放在这个框架下解释, 比如上一节的得分匹配与著名的扩散模型.
15 Score-Based Models
15.1 Continuous denoising
在训练去噪得分匹配模型 (DSM) 的时候, 我们会向真实分布中添加不同级别的噪声. 其中, 较强的噪声可以让样本分布 “填充” 整个空间, 适合采样过程的早期; 较弱的噪声更好地保持原本分布的细节, 适合采样过程的后期.
如果我们令噪声层级 \(L\to\infty\), 直观上看,
- 我们实际上是向 \(p(x)\) 中连续、逐渐地加入 Gauss 噪声, Gauss 噪声的方差连续增大.
- 采样的过程由 “分层” 退火 Langevin 就变成了 “连续” 退火 Langevin, 其中随机噪声强度逐渐减小.
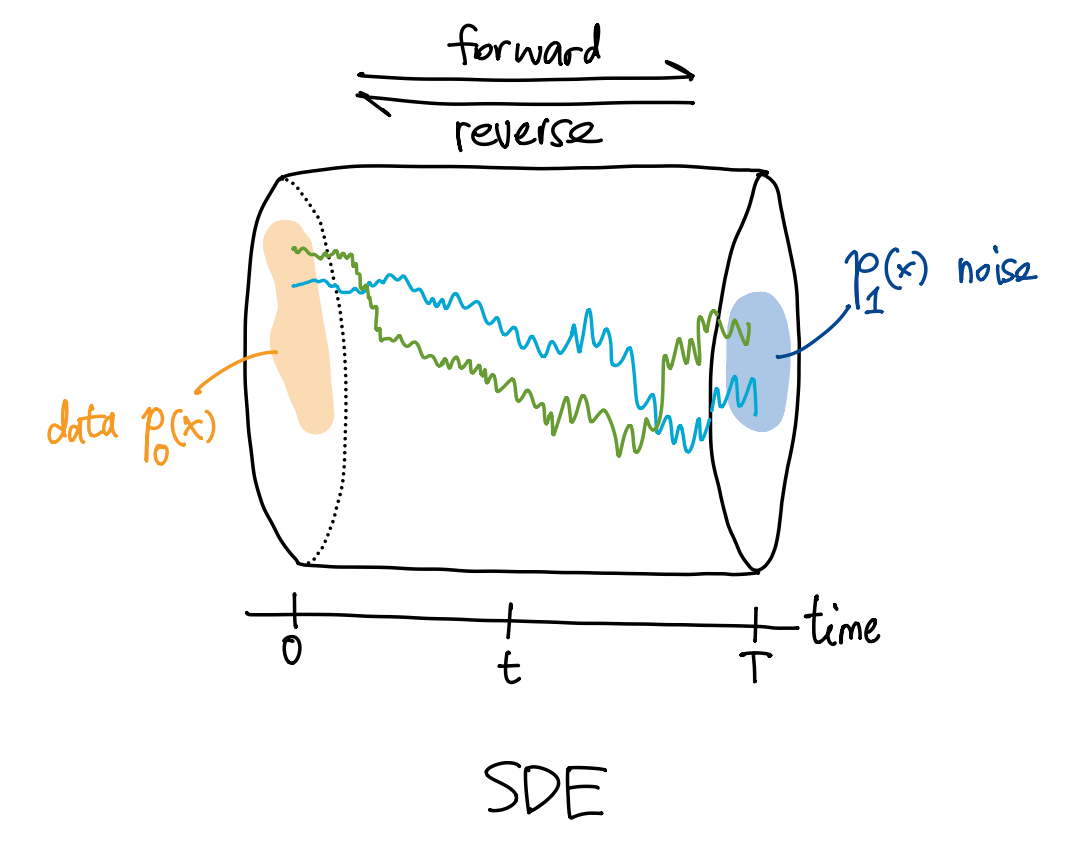
加噪过程可以用一个 SDE 描述, 称为正向过程 (forward process), \[ \dd{x_t} = {f(x_t,t) \dd{t}} + {g(t) \dd{w_t}}, \] 其中映射 \(f(-,t):\R^N\to\R^N\) 称为漂移系数 (drift coefficient), 函数值 \(g(t)\in\R\) 称为扩散系数 (diffusion coefficient), 随机过程 \(w_t\) 是 Wiener 过程, 时间 \(t\in[0,T]\).
- 当 \(f(x,t)\equiv0\) 时, \(x_t\) 的均值不随时间变化.
- \(g(t)\) 控制加噪强度.
令加噪过程 “时间倒流”, 我们就得到了采样 (去噪) 过程. 任何一个 SDE
都对应一个时间逆转版本. 去噪过程的 SDE 就是加噪过程的 SDE 的逆转版本
其中 \(p_t(x)\) 是 \(x_t\) 的密度函数, 橙色部分是得分函数.
15.2 Score matching
为了求解逆向过程, 我们需要求解 \(\nabla_x \log p_t(x)\). 我们仍旧使用得分匹配去训练 \(s_\theta(x,t)\approx\nabla_x \log p_t(x)\). 损失函数是加权的 \(\ell^2\) 损失 \[ \mathcal{L}(\theta) := \operatorname{E}_{t\sim U[0,T]} \operatorname{E}_{x_t \sim p_t} \Bigl[ \lambda(t) \bigl\Vert \nabla_{x_t}{\log p_t(x_t)} - s_\theta(x_t,t) \bigr\Vert_2^2\Bigr], \] 其中 \(\lambda:[0,T]\to(0,+\infty)\) 是权重函数, 分布 \(p_t(x)\) 通过在真实分布 \(p(x)\) 上应用正向过程算得.
15.3 Solving the reverse SDE
当我们训练好了 \(s_\theta(x,t)\), 就可以把它代入逆向过程 SDE \[ \dd{x}_t = {\bigl[ f(x_t,t) - g^2(t) \orange{s_\theta(x,t)} \bigr]\dd{t}} + g(t)\dd{\bar{w}_t}, \] 从先验分布采样 \(x_T\sim\pi\), 再求解 SDE 得到 \(\hat{x}_0\). 记 \(\hat{x}_0\sim p_\theta\). 当模型训练得足够好的时候, \(p_\theta(x)\) 近似等于真实分布 \(p(x)\), 此时 \(\hat{x}_0\) 便可以视作 \(p(x)\) 的一个样本了.
采样的过程需要求解逆向 SDE. 最简单的办法就是 Euler-Maruyama 法. 类似于 ODE 的 Euler 法, Euler-Maruyama 法取初始时间 \(t=T\) 和初值 \(x\sim\pi\) 并进行迭代 \[ \Align{ \Delta x &\gets {\bigl[ f(x,t) - g^2(t) \orange{s_\theta(x,t)} \bigr] \Delta t} + g(t)\sqrt{\smash{|\Delta t|}\vphantom{f}}\,z_t, \\ x &\gets x + \Delta x, \\ t &\gets t + \Delta t, } \] 其中 \(\Delta t<0\) (时间从 \(T\) 到 \(0\)), 噪声 \(z_t\sim\mathcal{N}(0,I)\) 相互独立.
15.4 Probability flow
在采样时, 我们需要用 Euler-Maruyama 法慢慢迭代, 通常需要上千步. 有没有快一点的方法?
可以证明, 逆向过程的 \(x_t\) 的分布密度 \(p_t(x)\) 满足如下 ODE, \[ \eval{\dv{x}{t}}_t = f(x,t) - \frac12 g^2(t) \orange{\nabla_x \log p_t(x)}. \]
这个 ODE 称为 probability-flow ODE (PF-ODE).
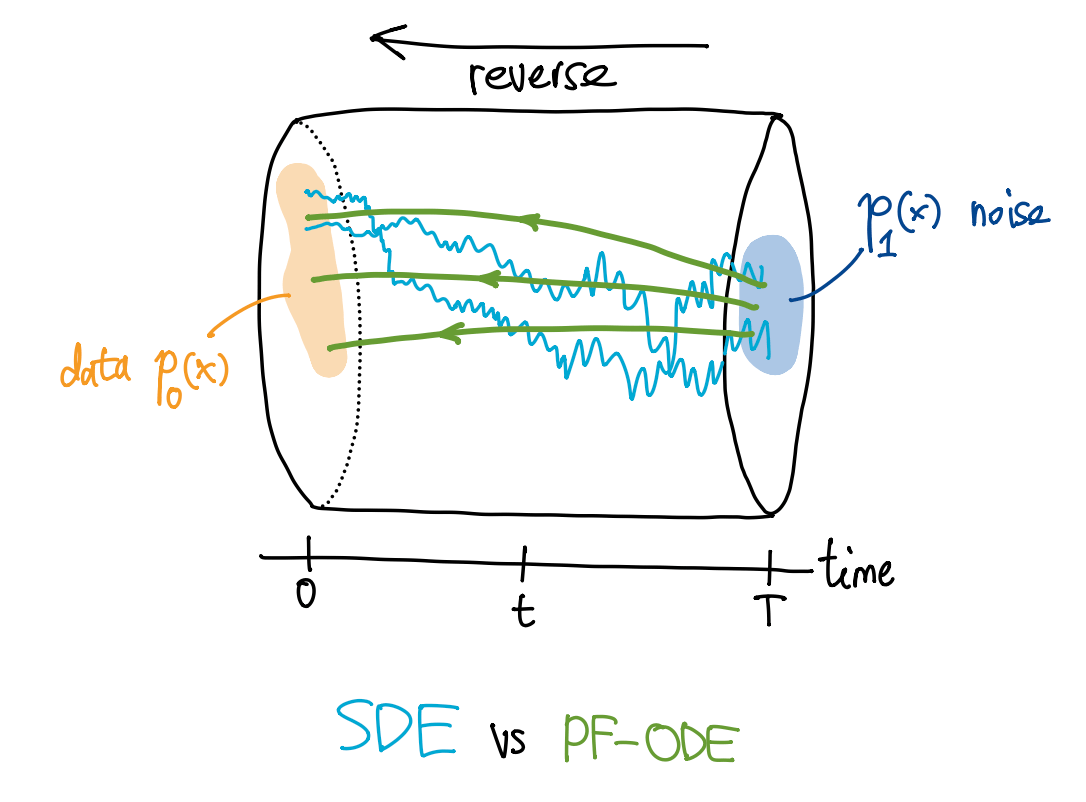
Note SDE vs PF-ODE.
想象你向一条湍急的河中滴入了一滴墨水 (初始数据分布 \(p_0\)).
- SDE (微观视角): 如果盯住其中单个墨水分子, 其轨迹是随机、曲折的. 它既被河水的整体流向 (漂移项) 带着走,又因为分子间的随机碰撞 (布朗运动 / 扩散项) 而抖动.
- PF-ODE (宏观视角): 不看单个分子, 而是退后一步, 看整滴墨水在水中扩散开来的浓度轮廓 (概率密度 \(p_t\)). 随着时间推移, 高浓度区域向低浓度区域平滑地晕染开, 同时随着河水漂移. 概率密度的演化平滑且确定.
PF-ODE 构建了一个确定的流场 \(v(x,t)\) (速度场). 如果让微粒不再做任何随机碰撞, 而是严格沿着 \(v(x,t)\) 的流线运动, 那么在任何时刻 \(t\), 这些微粒构成的宏观浓度分布, 与包含随机碰撞的 SDE 产生的浓度分布完全一模一样.
简而言之, PF-ODE 是一个剥离了随机性, 却能完美复刻 SDE 概率密度演化过程的确定性系统.
逆向 SDE 中的随机噪声决定了其采样步长 \(\Delta t\) 不能太大, 否则随机噪声的方差就会爆炸, 导致样本偏离高密度数据流形, 生成完全损坏的图像. 而 PF-ODE 的流线比较平滑, 我们可以使用较大的 \(\Delta t\). 此外, 已经有许多成熟的 ODE 数值求解器, 例如 Runge-Kutta, 可以达到很高阶的精度.
- 研究人员针对扩散模型的 PF-ODE 结构, 设计了专用的精确求解器 (DPM-Solver 系列). 其利用了 Taylor 展开精确抵消高阶误差, 能将原本 \(1000\) 步的采样压缩到 \(10\) 到 \(20\) 步, 且几乎不损失生成质量.
Note Score-based models 总结.
- 向真实分布逐渐地、连续地加入噪音, 用 SDE 建模这个过程.
- 训练: 使用神经网络拟合加噪分布的对数梯度 (score).
- 采样:
- A. 使用逆向过程逐步将噪音推到真实分布.
- B. 求解概率流 ODE, 快速地将噪音推到真实分布.
16 Diffusion Models
下面考虑两种特殊的正向 SDE, 它们分别对应上一篇介绍的去噪得分匹配和扩散模型.
16.1 VE-SDE
Variance-exploding SDE (VE-SDE). 取 \(g(t)=\sigma(t)\) 为任意递增的正值函数且 \(f(x,t)\equiv0\), 我们得到 \[ \Align{ &\textsf{(正向)} & \dd{x_t} &= \sigma(t) \dd{w_t}, \\ &\textsf{(逆向)} & \dd{x_t} &= {-\sigma^2(t) \nabla_{x}\log p_t(x_t) \dd{t} } + \sigma(t)\dd{\bar{w}_t}. } \] VE-SDE 之所以被称为 “方差爆炸的 SDE”, 其特点是
- 纯扩散: 由于漂移项为零, VE-SDE 描述的是一个纯粹的布朗运动过程 (\(\dd{x_t}\propto\dd{w}_t\)), 没有恢复力或系统性的收缩.
- 方差爆炸: 随着时间 \(t\) 的推移, 扩散强度 \(g(t)\) 不断增大, 导致数据分布的方差不断增加, “爆炸” 直到 \(t=T\) 时变成一个方差巨大的 Gauss 分布.
例如, 当 \(\sigma(t):=\exp(t)\) 时, 就得到了类似于去噪得分匹配中等比数列 \(\sigma_1<\sigma_2<\dots<\sigma_L\) 加噪策略. 对逆向过程使用 Euler-Maruyama 离散化, 就可以得到去噪得分匹配中的 “退火 Langevin 动力学”.
16.2 VP-SDE
Variance-preserving SDE (VP-SDE). 取 \(f(x,t)=-\frac12\beta(t)x\) 和 \(g(t)=\sqrt{\beta(t)}\), 其中 \(\beta(t)>0\). 此时 \[ \Align{ &\textsf{(正向)} & \dd{x_t} &= {- \frac12 \beta(t) x_t \dd{t}} + \sqrt{\smash{\beta(t)}\vphantom{f}} \dd{w_t}, \\ &\textsf{(逆向)} & \dd{x_t} &= {\biggl[ - \frac12\beta(t)x_t - \beta(t)\nabla_{x}\log p_t(x_t) \biggr]\dd{t}} + \sqrt{\smash{\beta(t)}\vphantom{f}} \dd{\bar{w}_t}. } \]
VP-SDE 称为 “方差保持的 SDE”, 的特点是
- 既有漂移又有扩散: 在布朗运动的基础上, 漂移项 \(-1/2\beta(t)x_t\) 让 \(x_t\) 向原点运动.
- 方差有界.
16.3 DDPM
16.3.1 Noising-adding
我们首先来求解 VP-SDE 的正向过程, 这对应了 DDPM 的加噪过程.
VP-SDE 是一个线性的 SDE, 我们可以求出它的解析解. 使用积分因子 \(\exp(\frac{1}{2}\int_0^t\beta(s)\dd{s})\), 解得 \[ x_t = x_0 \exp\left(-\frac{1}{2}\int_0^t \beta(s)\dd{s}\right) + \int_0^t \exp\left(-\frac{1}{2}\int_s^t \beta(r)\dd{r}\right) \sqrt{\beta(s)} \dd{w_s}. \] 为了与 DDPM 的符号对应, 我们定义连续时间下的累积信噪比参数 \(\bar{\alpha}(t):=\exp(-\int_0^t \beta(s)\dd{s})\). 根据 Itô isometry, 上式右侧积分项是一个 Gauss 随机变量, 其均值为 \(0\), 方差为 \[ V = \int_0^t \exp\left(-\int_s^t \beta(r)\dd{r}\right) \beta(s) \dd{s} = \int_0^t \frac{\bar{\alpha}(t)}{\bar{\alpha}(s)} \beta(s) \dd{s}, \] 由于 \(\dv{s}(\frac{1}{\bar{\alpha}(s)}) = \frac{\beta(s)}{\bar{\alpha}(s)}\), 上述积分刚好等于 \(\bar{\alpha}(t)[\frac{1}{\bar{\alpha}(t)} - 1 ] = 1 - \bar{\alpha}(t)\).
因此, 连续时间的边缘转移概率 (加噪公式) 为 \[ p(x_t\mid x_0) = \mathcal{N} \left( x_t; \sqrt{\bar{\alpha}(t)}x_0, (1 - \bar{\alpha}(t))I \right). \] 我们可以直接写成重参数化形式, \[ x_t = \sqrt{\bar{\alpha}(t)}x_0 + \sqrt{1 - \bar{\alpha}(t)}\varepsilon_t, \quad \varepsilon_t\sim \mathcal{N}(0, I). \] 这与 DDPM 论文中给出的离散版本的加噪公式一致.
16.3.2 Noise prediction
下面我们推导得分函数的形式.
对高斯分布求导得到条件得分函数为 \[ \nabla_{x_t} \log p(x_t \mid x_0) = -\frac{x_t - \sqrt{\bar{\alpha}(t)}x_0}{1 - \bar{\alpha}(t)}, \] 代入前面的重参数化公式 \(x_t - \sqrt{\bar{\alpha}(t)}x_0 = \sqrt{1 - \bar{\alpha}(t)}\varepsilon\), 便得到得分函数与注入噪声 \(\varepsilon\) 之间的关系: \[ \nabla_{x_t} \log p_t(x_t) \approx \nabla_{x_t} \log p(x_t \mid x_0) = -\frac{\varepsilon_t}{\sqrt{1 - \bar{\alpha}(t)}}. \]
因此, 训练得分函数估计器 \(s_\theta(x_t,t)\), 即得分匹配, 本质上等价于训练一个神经网络 \(\varepsilon_\theta(x_t, t)\) 去预测噪声: \[ s_\theta(x_t, t) = -\frac{\varepsilon_\theta(x_t, t)}{\sqrt{1 - \bar{\alpha}(t)}}. \] 其中 \(\varepsilon_\theta(x_t, t)\) 正是 DDPM 的训练对象.
得分匹配的训练目标是加权的 \(\ell^2\) 损失, 将 \(s_\theta(x_t,t)\) 代入即 \[ \mathcal{L}(\theta) := \operatorname{E}_{t\sim U[0,T]} \operatorname{E}_{x_t \sim p_t} \Biggl[ \frac{\lambda(t)}{\sqrt{1-\bar\alpha(t)}} \bigl\Vert \varepsilon_t - \varepsilon_\theta(x_t,t) \bigr\Vert_2^2 \Biggr], \] (其中 \(x_t\) 需根据加噪公式得到) 这与 DDPM 论文中由 KL 散度推出的损失函数一致.
16.3.3 Denoising
将逆向过程 SDE 离散化就可以得到 DDPM 的去噪公式.
将我们训练的得分网络 \(s_\theta(x_t, t)\) 代入逆向 SDE, 得到 \[ \dd{x_t} = \left[ -\frac{1}{2}\beta(t)x_t +\beta(t) \frac{\varepsilon_\theta(x_t, t)}{\sqrt{1 - \bar{\alpha}(t)}} \right]\! \dd{t} + \sqrt{\beta(t)} \dd{\bar{w}_t}. \] 使用 Euler-Maruyama 法, \[ x_{t - \Delta t} = x_t + \left[ \frac{1}{2}\beta(t)x_t -\beta(t) \frac{\varepsilon_\theta(x_t, t)}{\sqrt{1 - \bar{\alpha}(t)}} \right] \Delta t + \sqrt{\beta(t)\Delta t} \cdot z_t, \] 其中噪声 \(z_t\sim\mathcal{N}(0,I)\) 相互独立. 在 DDPM 中, 我们定义时间步 \(i = 1, 2, \dots, N\). 令 \(\beta_i := \beta(t_i)\Delta t\). 对上式稍加整理, 便得到 \[ x_{i-1} = \left( 1 + \frac{1}{2}\beta_i \right) x_i - \frac{\beta_i}{\sqrt{1 - \bar{\alpha}_i}} \varepsilon_\theta(x_i, i) + \sqrt{\beta_i} z_i \] 把 DDPM 的去噪公式拿过来对比, \[ x_{i-1} = \frac{1}{\sqrt{\alpha_i}}\left( x_i - \frac{\beta_i}{\sqrt{1 - \bar{\alpha}_i}} \right) \varepsilon_\theta(x_i, i) + \sqrt{\beta_i} z_i, \] 两者还略有出入. 为了与 DDPM 保持一致, 我们使用一个 Taylor 展开技巧. 当时间步长 \(\Delta t\to0\) 时, 每一步的噪声率 \(\beta_i=\mathcal{O}(\Delta t)\) 也趋于零, 我们有 \[ 1/\sqrt{\alpha_i} = (1-\beta_i)^{-1/2} = 1-\left(-\frac{1}{2}\beta_i\right) + \mathcal{O}(\Delta t^2), \] 代入 DDPM 去噪公式, 得到 \[ x_{i-1} = \left( 1 + \frac{1}{2}\beta_i + \mathcal{O}(\Delta t^2) \right) x_i - \left[ \frac {\beta_i + \mathcal{O}(\Delta t^3)} {\sqrt{1 - \bar{\alpha}_i}} \right] \varepsilon_\theta(x_i, i) + \sqrt{\beta_i} z_i, \] 略去高阶无穷小即与 Euler-Maruyama 得到的公式一致.
- Euler-Maruyama 方法是一种一阶数值近似方法. 对于漂移项, 它只保留到 \(\mathcal{O}(\Delta t)\) 的精度, 所有 \(\mathcal{O}(\Delta t^2)\) 及更高阶的项都会作为截断误差 (truncation error) 被直接舍弃.
总之, 我们可以得到去噪公式 \[ x_{i-1} = \frac{1}{\sqrt{\alpha_i}}\left( x_i - \frac{\beta_i}{\sqrt{1 - \bar{\alpha}_i}} \right) \varepsilon_\theta(x_i, i) + \sqrt{\beta_i} z_i. \] 至此, 我们已经用 SDE + 得分匹配的框架完整给出了 DDPM 的训练对象、训练目标以及采样过程.
16.4 DDIM
DDIM 与 DDPM 在建模与训练上完全相同, 只不过在采样上使用了效率更高的 PF-ODE.
直接写出 VP-SDE 逆向过程的 PF-ODE 为 \[ \dd{x_t} = \left[ -\frac{1}{2}\beta(t) x_t -\frac{1}{2}\beta(t) \nabla_{x_t} \log p_t(x_t) \right] \dd{t}, \] 将训练好的得分函数 \(\nabla_{x_t} \log p_t(x_t)=-\frac{\varepsilon_\theta(x_t, t)}{\sqrt{1 - \bar{\alpha}(t)}}\) 代入, 可以证明该微分方程等价于 \[ \dd{}\!\left( \frac{x_t}{\sqrt{\bar{\alpha}(t)}} \right) = \varepsilon_\theta(x_t, t) \, \dd{}\!\left( \frac{\sqrt{1-\bar{\alpha}(t)}}{\sqrt{\bar{\alpha}(t)}} \right). \]
使用显式 Euler 法, 假设在足够小的时间步长 \([s, t]\) 内, 神经网络的预测值 \(\varepsilon_\theta(x_t, t)\) 是一个常数, 方程两边同时在 \([s,t]\) 上积分, 解得 \[ x_s = \sqrt{\bar{\alpha}(s)} \left( \frac{x_t - \sqrt{1-\bar{\alpha}(t)}\varepsilon_\theta(x_t, t)} {\sqrt{\bar{\alpha}(t)}} \right) + \sqrt{1-\bar{\alpha}(s)} \varepsilon_\theta(x_t, t), \] 即 DDIM 采样的公式, 其中括号内的 \(\frac{x_t - \sqrt{1-\bar{\alpha}(t)}\varepsilon_\theta}{\sqrt{\bar{\alpha}(t)}}\) 正是模型在时刻 \(t\) 对原始样本 \(x_0\) 的预测. 整个公式的含义就是利用预测的 \(x_0\) 和当前估计的噪声, 按照时刻 \(s\) 的信噪比线性组合, 得到预测的 \(x_s\).
Brian D.O. Anderson, Reverse-time diffusion equation models, 1982.↩︎