信息论 | 1 信源编码
讯息源编码. 讯息源里可能有许多冗余, 我们需要找到一个尽可能短的讯息编码.
对数 \(\log\) 是以 \(2\) 为底的; \(\ln\) 表示以 \(\e\) 为底的对数.
Note (Jensen 不等式) 设随机变量 \(X\), 函数 \(f\) 为下凸函数 (类似 \(y=x^2\)), 则 \[ f(\operatorname{E}(X)) \leq \operatorname{E}(f(X)). \] 对于上凸函数 (类似 \(y=-x^2\)), 不等号变为 \(\geq\).
1 Entropy
1.1 Prefix codes
对于 \(n\) 元字符集 \(\{x_1,\dots,x_n\}\), 每个字符出现的概率分别为 \((p_1,\dots,p_n)\). 我们要寻找平均码长最短的字符编码 \(C=(c_1,\dots,c_n)\). 平均码长就是编码长度的期望 \[ L(C) := \sum_{i=1}^n p_i \ell_i. \] 我们考虑的当然不是任意的编码, 我们希望被编码的信息可以被唯一地还原. 记编码映射 \[ C : x_{i_1}\dots x_{i_k} \mapsto \underbrace{c_{i_1}\dots c_{i_k}}_{\textsf{concat}}. \] 编码 \(C\) 称为可唯一解码的 (uniquely decodable), 若 \(C\) 是单射. 一种特殊的可唯一解码的编码是前缀码 (prefix code), 即任意的 \(c_i\) 都不是 \(c_j\) (\(j\neq i\)) 的前缀.
- 二进制 prefix codes 与二叉树一一对应. 对于二叉树的每个非叶子结点, 它的左右子节点分别取 \(0,1\). 叶子结点对应字符的编码, 其编码的值为从根节点到该节点经历的 \(0,1\) 序列.
记 \(B\) 为所有 uniquely decodable codes 的集合, 子集 \(A\) 为所有的 prefix codes 的集合. 我们断言 (证明稍后给出):
- 对每个 \(C\in B\), 必然存在 \(\tilde{C}\in A\) 使得 \(L(\tilde{C})=L(C)\).
换言之, \[ \min_{C\in A}L(C) = \min_{C\in B}L(C), \] 我们只需在 \(A\) 中寻找. 而 \(A\) 中的码长满足如下不等式.
Theorem (Kraft 不等式) 设二进制 prefix code \(C=(c_1,\dots,c_n)\), 其长度分别为 \((\ell_1,\dots,\ell_n)\), 则 \[ \sum_{i=1}^n 2^{-\ell_i} \leq 1. \] 取等当且仅当编码对应的二叉树中, 每个节点都有 \(0\) 或 \(2\) 个子节点.
反之, 若非负整数列 \((\ell_1,\dots,\ell_n)\) 满足 Kraft 不等式, 则存在 prefix code \(C\) 以其为长度——以 \(\ell_i\) 为叶节点深度构造二叉树即可.
\[ \xymatrix@=5em{ *[F-,]{\hspace{3em}\mathclap{\textsf{Prefix code}}\hspace{3em}\strut} \ar@1{<->}[r] & *[F-,]{\hspace{3em}\mathclap{\textsf{二叉树}}\hspace{3em}\strut} \ar@1{<->}[r] & *[F-,]{\hspace{3em}\mathclap{\textsf{Kraft 不等式}}\hspace{3em}\strut} } \]
现在我们给出断言的证明, 它实际上是 Kraft 不等式的推广.
Theorem (Kraft-McMillan 不等式) 设二进制 uniquely decodable 编码 \(C=(c_1,\dots,c_n)\), 其长度分别为 \((\ell_1,\dots,\ell_n)\), 则 \[ \sum_{i=1}^n 2^{-\ell_i} \leq 1. \] 进而存在 prefix code \(\tilde{C}\), 使得其长度也为 \((\ell_1,\dots,\ell_n)\).
Pf 设 \(a_L\) 表示 \(C\) 可以编码成 (“拼成”) 的长度为 \(L\) 的 0/1 序列的个数. 由于不同拼接方式得到的 0/1 序列不同, 有 \(a_L\leq2^L\) (所有长度为 \(L\) 的 0/1 的序列的个数). 下面考虑 \(\{a_L\}\) 的生成函数.
记 \(S(x) = \sum_{i=1}^n x^{\ell_i}\), 则 “从 \(C\) 中选择 \(m\) 个码字 (可重复)” 的生成函数是乘积 \([S(x)]^m\), 其 \(L\) 次项系数就是得到长度 \(L\) 序列的方法数. 故 \[ \sum_{L=0}^\infty a_L x^L = \sum_{m=0}^\infty [S(x)]^m. \] 注意 \(a_L\leq2^L\), 级数在 \(|x|<1/2\) 时绝对收敛, 此时 \[ \Align{ \frac{1}{1-S(x)} = \sum_{m=0}^\infty [S(x)]^m = \sum_{L=0}^\infty a_Lx^L \leq \sum_{L=0}^\infty (2x)^L = \frac{1}{1-2|x|}, } \] 两遍取倒数并令 \(x\to(1/2)^-\) 即得.
1.2 Entropy
讯息集 (或字符集) \({\cal M}=\{m_1,\dots,m_n\}\), 每个讯息的概率为 \(p_i\). 对于编码 \(C=(c_1,\dots,c_n)\), 码长分别为 \(\ell_i\), 则平均码长为 \(\sum p_i\ell_i\). 根据以上的讨论, 我们只需在 prefix 编码中寻找. 换言之, 我们只需要找到一组满足 Kraft 不等式的非负整数. 为了让平均编码长度尽可能小, 需要 Kraft 不等式取等. 总之, 我们的优化问题为 \[ \min_{\ell_1,\dots,\ell_n} \sum_{i=1}^n p_i\ell_i, \quad \textsf{s.t.} \quad \sum_{i=1}^n 2^{-\ell_i}=1, \quad \ell_i\geq0. \] 注意我们把 \(\ell_i\in\N\) 的条件删去了.
令 \(q_i=2^{-\ell_i}\), 则 \((q_1,\dots,q_n)\) 也是一个概率分布. 优化问题变为 \[ \max_{q_1,\dots,q_n} \sum p_i\log q_i. \] 注意到
Theorem 设概率分布 \((p_1,\dots,p_n)\), \((q_1,\dots,q_n)\), 则 \[ \sum p_i\log(\frac{p_i}{q_i})\geq0, \] 也即 \[ \sum p_i\log p_i \geq \sum p_i\log q_i. \]
Pf 记 \(f(x):=\log{x}\), 则 \(f''(x)<0\), 即 \(f\) 为上凸函数. 由 Jensen 不等式, \[ \sum p_i \log\!\pqty{\frac{q_i}{p_i}} \leq \log\!\pqty{ \sum p_i\frac{q_i}{p_i} } = 0. \]
因此当 \(p_i=q_i\) 即 \(\ell_i=-\log p_i\) 时取到最大值, 平均码长为 \(- \sum p_i\log p_i\).
设讯息源 \(X\) 给出的各条讯息的概率为 \((p_1,\dots,p_n)\), 则它的熵 (entropy) 定义为 \[ H(X) := -\sum_{i=1}^n p_i \log p_i. \]
- 编码该讯息源的讯息, 所需的平均编码长度. 衡量了该讯息源的信息量的大小.
- 均匀分布的熵最大, 确定分布 (某 \(p_i=1\)) 的熵最小.
- 一条以 \(p_i\) 为概率的讯息的信息量 (最短平均码长) 为 \(-\log{p_i}\). 概率越小, 信息量越大.
- \(H(X)\) 的单位是 bit. 当然也可以以 \(n\) 进制编码, 需将 \(\log\) 换为以 \(n\) 为底, 单位也不再是 bit.
Theorem (熵的可加性) 设随机变量 \(X,Y,Z\) 的概率分布分别为 \[ \Align{ (p_1,\dots,p_n,a+b),\quad \pqty{\frac{a}{a+b},\frac{b}{a+b}},\quad (p_1,\dots,p_n,a,b), } \] 其中 \(a+b\neq0\). 则 \[ H(X) + (a+b) H(Y) = H(Z). \]
1.3 Constructing the optimal code
以上的讨论只是纯理论上的, 因为熵不要求编码长度是整数. 下面我们来构造实际上的最优编码.
根据以上讨论, 随机变量 \((p_1,\dots,p_n)\) 的最优编码 \((c_1,\dots,c_n)\) (平均码长最小) 应满足:
- 如果 \(p_1\leq\cdots\leq p_n\), 则 \(|c_1|\geq\cdots\geq|c_n|\).
- (Kraft) \(\sum_i 2^{-|c_i|}=1\).
- 由 1, 2, 必然有 \(|c_{n-1}|=|c_n|\), 不妨设 \(c_{n-1},c_n\) 是兄弟节点.
- 由 3, 如果 \((c_1,\dots,c_n)\) 是 \((p_1,\dots,p_n)\) 的最优编码 (\(p_1\geq\dots\geq p_n\)), 记 \(\tilde{c}_{n-1}\) 是 \(c_{n-1},c_n\) 的父节点对应的编码 (即两者的公共前缀), 则 \((c_1,\dots,c_{n-2},\tilde{c}_{n-1})\) 是 \((p_1,\dots,p_{n-2},p_{n-1}+p_n)\) 的最优编码.
由此构造出来的最优编码称为 Huffman 编码.
Theorem (最优编码的平均码长) 设 \(C^*\) 是随机变量 \(X\) 的最优 prefix-free 编码, 则 \[ H(X) \leq L(C^*) < H(X)+1. \]
Pf 考虑编码 \(C\), 其码长 \(\ell_i=\lceil\log\frac{1}{p_i}\rceil\), 注意到 \[ \sum_{i=1}^n 2^{-\ell_i} = \sum_{i=1}^n 2^{-\lceil\log\frac{1}{p_i}\rceil} \leq \sum_{i=1}^n 2^{-\log\frac{1}{p_i}} = \sum_{i=1}^n p_i = 1, \] 故可以构造以 \(\ell_i\) 为长度的 prefix-free 编码. 利用 \(-\log{p_i}\leq\ell_i<-\log{p_i}+1\), 容易得到 \[ H(X) \leq L(C) < H(X)+1 \] 由于 \(L(C^*)<L(C)\), 有 \(L(C^*)<H(X)+1\). 下界由熵的定义直接得到.
2 Joint entropy, conditional entropy, mutual information and KL-divergence
2.1 Joint entropy
设 (有限支) 随机变量 \(X,Y\) 的联合分布为 \((p_{ij})_{n\times m}\), 则联合熵 (joint entropy) 定义为 \[ H(X,Y) = -\sum_{i,j} p_{ij} \log{p_{ij}}. \]
- 与各个随机变量的熵的关系: \[ H(X,Y) \leq H(X) + H(Y). \] 取等当且仅当 \(X,Y\) 独立. 特别地, 若 \(X=Y\), 则 \(H(X,Y)=H(X)=H(Y)\).
2.2 Conditional entropy
在 \(Y=y\) 的条件下, \(X\) 有条件分布. 定义 \[ H(X\mid Y=y) := -\sum_i P(X=x_i\mid Y=y) \log{P(X=x_i\mid Y=y)}. \] 条件熵 (conditional entropy) 定义为 \[ \Align{ H(X\mid Y) :=&\; \sum_j P(Y=y_j) H(X\mid Y=y_j) \\ =&\; -\sum_{i,j} P(X=x_i,Y=y_j)\log{P(X=x_i\mid Y=y_j)}. } \]
如果 \(X,Y\) 独立, 则 \(H(X\mid Y)=H(X)\). 如果 \(X=Y\), 则 \(H(X\mid Y)=0\).
条件熵的含义是, 知道其中一个随机变量, 则另一个随机变量的信息量大小. 条件熵与联合熵的关系: \[ \Align{ H(X,Y) &= H(Y\mid X) + H(X) = H(X\mid Y) + H(Y). } \]
于是我们有 \[ \Align{ H(Y)&\geq H(Y\mid X), & H(X)&\geq H(X\mid Y). } \] 即 conditioning reduces entropy. 并且有 \[ H(Y) - H(Y\mid X) = H(X) - H(X\mid Y), \] 左边可以看作 "\(Y\) 中包含 \(X\) 的信息量", 右边可以看作 "\(X\) 中包含 \(Y\) 的信息量". 两者相等.
Theorem (链式法则) 对于随机变量列 \(\{X_i\}_{i=1}^n\), 有 \[ H(X_1,\dots,X_n)=\sum_{i=1}^n H(X_i\mid X_1,\dots,X_{i-1}). \] 特别地, 若 \(\{X_i\}\) 相互独立, 则 \[ H(X_1,\dots,X_n) = \sum_{i=1}^n H(X_i). \]
2.3 Mutual information
互信息 (mutual information) 就定义为 \[ \Align{ I(X;Y) :=&\; H(Y) - H(Y\mid X) \\ =&\; \sum_{i,j} P(X=x_i,Y=y_i) \log\frac{P(X=x_i,Y=y_i)}{P(X=x_i)P(Y=y_i)}. } \] 它是对称的, 衡量了 \(X,Y\) 相互包含的信息量的大小. 有 \[ \Align{ I(X;Y) &= H(Y) - H(Y\mid X) \\ &= H(X) - H(X\mid Y) \\ &= H(X) + H(Y) - H(X,Y). } \]
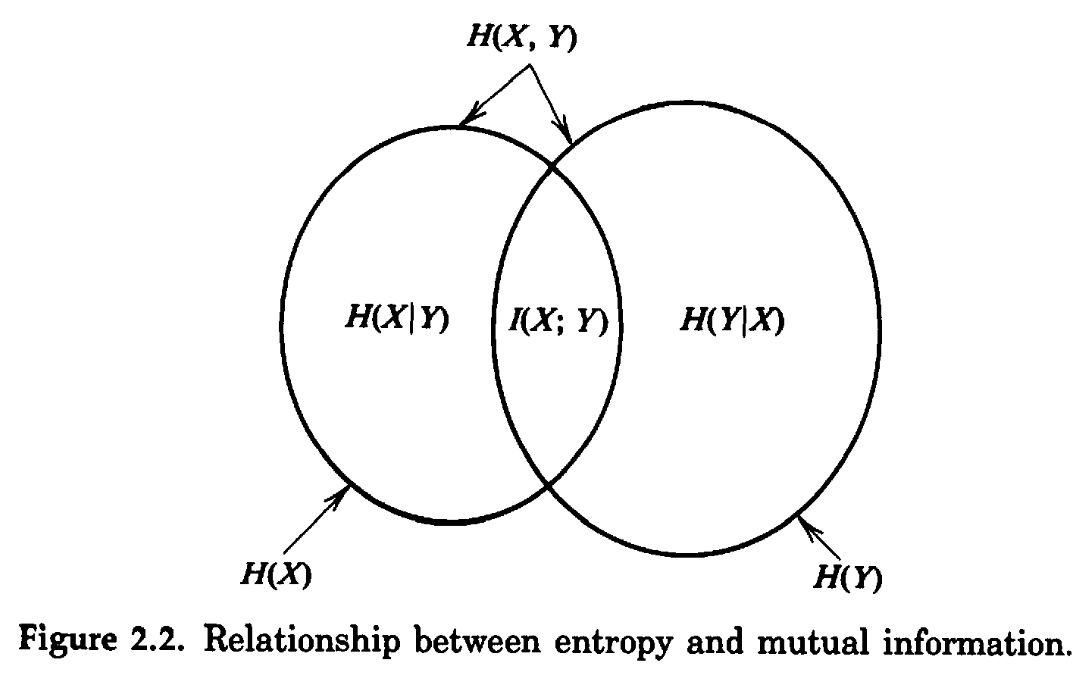
2.4 Kullback-Leibler divergence
假设随机变量 \(X\) 真正的概率分布为 \(P=(p_1,\dots,p_n)\) (未知). 我们用另一个分布 \(Q=(q_1,\dots,q_n)\) 来估计它. 故我们实际采取的编码长度为 \((-\log{q_1},\dots,-\log{q_n})\), 实际的平均编码长度为 \(-\sum_i p_i\log{q_i}\). 而理论最优编码长度为 \(-\sum_ip_i\log{p_i}\). 两者的差值为 \[ \sum_i p_i \log\frac{p_i}{q_i} \geq 0, \] (回顾第 1 节中的不等式) 它称为 \(P\) 与 \(Q\) 的 KL 散度 (Kullback-Leibler divergence), 记作 \(D(P\parallel Q)\) 或者 \(\operatorname{KL}(P\parallel Q)\).
- KL 散度也称为相对熵 (relative entropy).
- 互信息实际上是联合分布 \(P((X,Y)=(x_i,y_i))\) 与乘积分布 \(P(X=x_i)P(Y=y_i)\) 间的 KL 散度.
记 \(n\) 元概率分布列的空间 \({\cal P}_n:=\{x\in\R^n\mid\sum x_i=1,x_i>0\}\). 这是 \(\R^n\) 中的 \((n-1)\) 维凸流形.
Theorem (熵和 KL 散度的凹凸性) 设 \(P,Q\in{\cal P}_n\).
- \(H(P)\) 关于 \(P\) 是上凸函数 (类似 \(y=-x^2\)).
- \(D(P\parallel Q)\) 关于 \(P\) 和 \(Q\) 以及 \((P,Q)\) 都是下凸函数 (类似 \(y=x^2\)).
注: “凹凸性” 的术语一直没有固定的标准, 这里的 “上凸” / “下凸” 的意思是函数图像向上 / 向下弯曲.
Pf 求出其 Hessian 即可. 正定为下凸, 负定为上凸. 实际上有 \[ \Align{ \pqty{\pdv[2]{H}{p_i}{p_j}} &= -\delta_{ij} \frac{1}{p_i}, & \pqty{\pdv[2]{D}{x_i}{x_j}} &= \pmqty{ \pqty{\delta_{ij}\frac{1}{p_i}} & \pqty{-\delta_{ij}\frac{1}{q_i}} \\ \pqty{-\delta_{ij}\frac{1}{q_i}} & \pqty{\delta_{ij}\frac{p_i}{q_i^2}} }. } \] 熵 \(H(P)\) 的 Hessian 显然是负定的. 对于 KL 散度的 Hessian, 注意到对角线上的两个块都是正定的, 故 \(D\) 关于 \(P\) 和 \(Q\) 是下凸函数; 而整个 Hessian 是半正定的 (Schur 补定理), 故 \(D\) 关于 \((P,Q)\) 是下凸函数.
期末考试的参考答案提供了另一种证明方法.
向量范数与 KL 散度的关系:
Theorem (\(\ell^1\) 范数被 KL 散度控制) 设 \(P,Q\in{\cal P}_n\), 则 \[ \frac1{2\ln2}\|P-Q\|_1^2 \leq D(P\parallel Q). \]
Pf 首先考虑最简单的分布, 即 Bernoulli 分布的情况. 设 \(P=(p,1-p)\), \(Q=(q,1-q)\), 不妨有 \(p\geq q\). 则 \[ \Align{ D(P\parallel Q) - \frac1{2\ln2}\|P-Q\|_1^2 &= \pqty{p\log\frac{p}{q} + (1-p)\log\frac{1-p}{1-q}} - \frac{2}{\ln2}(p-q)^2, \\ &=: f(p,q). } \] 只需证明 \(f(p,q)\geq0\). 关于 \(q\) 求导得到 \[ \pdv{f}{q} = \frac{q-p}{q(1-q)\ln2} - \frac{4}{\ln2}(q-p) \leq 0, \] (注意 \(q(1-q)\leq\frac14\) 以及 \(q\leq p\)) 于是 \(f\) 关于 \(q\) 递减. 当 \(q=p\) 时, \(f(p,q)=0\), 即证.
接着考虑一般的分布 \(P=(p_i)\), \(Q=(q_i)\). 构造 \[ \tilde{P} = \pqty{ \sum_{i:p_i\geq q_i} p_i,\sum_{i:p_i<q_i}p_i }, \] 则 \(\tilde{P}\), \(\tilde{Q}\) 都是 Bernoulli 分布, 并且 \(\|P-Q\|_1=\|\tilde{P}-\tilde{Q}\|_1\). 注意 KL 散度关于 \(P,Q\) 都是下凸的, 有 \[ D(P\parallel Q) \geq D(\tilde{P}\parallel\tilde{Q}) \geq \frac{1}{2\ln2}\|\tilde{P}-\tilde{Q}\|_1^2 = \frac{1}{2\ln2}\|P-Q\|_1^2. \]
3 Entropy Rate
考虑这样一个随机变量 \(X\sim P=(0.01,0.99)\), 它的熵 \(H(X)\approx0.08\), 然而最短一次传输的平均编码长度 (需要是正整数) 为 \(1\) bit. 它的编码效率是 \(0.08/1=0.08\).
如果有无穷长度的讯息序列 \((X_1,X_2,\dots,X_t,\dots)\sim{\sf iid}\,P\), 能否有一种编码长度更短的方式? 我们考虑将相邻的 \(T\) 个讯息源一起编码: \((X_1,\dots,X_T)\), 则它们的联合熵 \(H(X_1,\dots,X_T)=T\cdot H(X_1)\), 进而最短平均编码长度小于等于 \(T\cdot H(X)+1\) bit. 它的编码效率是 \[ \frac{T\cdot H(X) + 1}{T\cdot H(X)} = 1+\mathcal{O}\!\pqty{\frac1T}, \] 平均到每个 \(X_i\) 的最短平均码长是 \[ \frac{T\cdot H(X)+1}{T} = H(X) + \mathcal{O}\!\pqty{\frac1T}. \]
Huffman 编码是固定一次编码的随机变量个数 \(T=1\) 情况下的最优解; 而熵给出了 \(T\) 可变时的理论最优解.
下面给出熵率的严格定义. 将讯息源 \(\mathcal{X}\) 建模为随机过程 (stochastic process), 即随机变量序列 \(\{X_i\}_{i\in\N}\). 讯息源 \({\cal X}\) 的熵率 (entropy rate) 为 \[ H({\cal X}) := \lim_{T\to\infty} \frac1T H(X_1,X_2,\dots,X_T). \] 随机过程 \(\mathcal{X}\) 称为平稳的 (stationary), 若联合分布在平移下不变: \[ p(x_1,\dots,x_n) = p(x_{t+1},\dots,x_{t+n}),\quad \forall t,n\geq1. \] 特别地, 此时 \(X_i\) 同分布. 如果 \(X_i\) 独立同分布, 也可以推出 \(\mathcal{X}\) 是平稳的.
Theorem (等价定义) 平稳过程 \(\{X_i\}\) 的熵率等于条件熵的极限, \[ H(\mathcal{X}) = \lim_{T\to\infty} H(X_T\mid X_1,\dots,X_{T-1}). \]
Pf 首先注意到 \[ \Align{ H(X_T\mid X_1,\dots,X_{T-1}) &\leq H(X_T\mid X_2,\dots,X_{T-1}) \\ &= H(X_{T-1}\mid X_1,\dots,X_{T-1}), } \] (第二个步利用了平稳性) 因此序列 \(a_T:=H(X_T\mid X_1,\dots,X_{T-1})\) 递减且有下界 \(0\), 极限存在. 根据链式法则, \[ \frac{H(X_1,X_2,\dots,X_T)}{T} = \frac{1}{T}\sum_{i=1}^T H(X_i\mid X_1,\dots,X_{i-1}) = \frac{1}{T}\sum_{i=1}^T a_i, \] 由于收敛序列的算术平均值序列收敛原序列的极限, 定理得证.
4 Differential Entropy
4.1 Differential entropy
对连续的随机变量也可以定义熵.
然而, 连续的随机变量有无穷大的信息量. 比如, 我们将一个连续随机变量 \(X\sim U[0,1]\) 离散化: \[ X_n \sim U\bqty{\frac1n,\frac2n,\dots,\frac{n-1}n,1}, \] 其中 \(n\in\N^*\). 它的熵 \(H(X_n)=-\sum_{i=0}^n\frac1{n}\log\frac1{n}=-\log\frac1{n}\). 当 \(n\to\infty\) 时, \(H(X_n)\to+\infty\).
那我们只好先放弃熵的物理含义, 从形式上定义随机变量的熵. 在形式上, 只需要把离散的求和改为积分. 设连续随机变量 \(X\) 的密度为 \(p(x)\), 则 \(X\) 的微分熵 (differential entropy)定义为 \[ h(X) := -\int_\R p(x) \log p(x) \dd{x}. \]
- 对数可以是以 \(2\) 为底的 \(\log\), 也可以是自然对数 \(\ln\), 没有本质区别.
微分熵和离散化 \(X_n\) 有如下关系. 设 \(X\) 是 \([0,1]\) 上的连续随机变量, 密度为 \(p(x)\), 定义 \[ X_n \sim Q=\pqty{ q_i }_{i\in\Z}, \] 其中 \[ q_i = P\!\pqty{\frac{i}{n} \leq X < \frac{i+1}{n}} = \int_{i/n}^{(i+1)/n} p(x)\dd{x}. \] 根据中值定理, 存在 \(x_i\in[i/n,(i+1)/n]\) 使得 \(q_i=p(x_i)\cdot1/n\), 于是有 \[ \Align{ H(X_n) &= -\sum_{i\in\Z} q_i \log{q_i} \\ &= -\sum_{i\in\Z} \frac{p(x_i)}{n} [\log{p(x_i)} - \log(n)] \\ &= -\frac{1}{n} \sum_{i\in\Z} p(x_i) \log{p(x_i)} + \sum_{i\in\Z} q_i \log(n) \\ &= \blue{-\frac{1}{n} \sum_{i\in\Z} p(x_i) \log{p(x_i)}} + \log(n). } \] 另一方面, 连续随机变量 \(X\) 的熵为 \[ h(X) = \lim_{n\to\infty} \biggl[ \blue{-\frac{1}{n}\sum_{i\in\Z} p(x_i) \log p(x_i)} \biggr], \] 我们得到了如下定理.
Theorem (微分熵与熵的关系) 记号承上, 则 \[ h(X) = \lim_{n\to\infty}[ H(X_n) - \log(n) ]. \]
4.2 Properties
离散的随机变量的熵在非退化变换下不变: 设 \(a,b\in\R\), \(a\neq0\), 则 \[ H(aX+b) = H(X). \] 这是符合熵的实际含义的.
对于连续随机变量 \(X\), 平移不改变其熵: \[ h(X+b) = h(X). \] 然而, 它的熵随 \(X\) 的缩放而改变 (\(a>0\)): \[ \Align{ h(aX) = -\int_\R \frac{1}{a} p\!\pqty{\frac{x}{a}} \log\bqty{ \frac{1}{a} p\!\pqty{\frac{x}{a}} } \dd{x} = h(X) + \log{a}, } \] 主要是因为微分熵只是形式上的定义, 不具有明确的物理含义.
Example 多元正态分布 \(X\sim N(0,\Sigma)\) 的熵: \[ \Align{ h(X) &= -\int_{\R^n} p(x) \ln{p(x)}\dd{x} \\ &= \frac12\int_{\R^n} p(x) \bqty{ \ln((2\pi)^n\det\Sigma) + x\T\Sigma^{-1}x } \dd{x} \\ &= \frac12 \bqty{ \ln((2\pi)^n\det\Sigma) + \operatorname{E}(X\T\Sigma^{-1}X) }. } \] 只需求出 \(\operatorname{E}(X\T\Sigma^{-1}X)\). 设正定矩阵分解为 \(\Sigma=CC\T\), 令 \(Y:=C^{-1}Z\), 则 \(Y\) 的期望为零, 协方差为单位阵 \(I_n\). 于是 \[ \operatorname{E}(X\T\Sigma^{-1}X) = \operatorname{E}(Y\T Y) = \sum_{i=1}^n \operatorname{E}(Y_i^2) = \sum_{i=1}^n \operatorname{Var}(Y_i) = n. \] 因此 \[ h(X) = \frac12 \bigl[ \ln((2\pi)^n\det\Sigma) + n \bigr] = \frac12 \ln((2\pi\e)^n\det\Sigma). \] 由于微分熵关于平移不变, 正态分布 \(N(\mu,\Sigma)\) 的熵也等于它.
4.3 Joint / conditional differential entropy, mutual information and KL-divergence
联合微分熵和联合条件熵的定义是很直接的: \[ \Align{ h(X,Y) &:= -\int_{\R^2} p_{X,Y}(x,y) \log{p_{X,Y}(x,y)} \dd{x}\dd{y}, \\ h(X\mid Y) &:= -\int_{\R^2} p_{X,Y}(x,y) \log{p_{X\mid Y}(x\mid y)} \dd{x}\dd{y}. \\ } \] 互信息定义为 \[ \Align{ I(X;Y) :=&\; h(X) - h(X\mid Y) \\ =&\; h(Y) - h(Y\mid X) \\ =&\; h(X) + h(Y) - h(X,Y) \\ =&\; \int_{\R^2} p_{X,Y}(x,y) \log\frac{p_{X,Y}(x,y)}{p_X(x)p_Y(y)} \dd{x}\dd{y}. } \] 概率密度函数 \(f,g\) 的 KL 散度定义为 \[ D(f\parallel g) := \int_{\R} f(x)\log\frac{f(x)}{g(x)} \dd{x}. \]
Theorem (离散与连续随机变量的 KL 散度) 将 \(f,g\) 对应的随机变量 \(X,Y\) 离散化, 得到 \(X_n,Y_n\) 概率分布 \(P_n,Q_n\), 则 \[ D(f\parallel g) = \lim_{n\to\infty} D(P_n,Q_n). \] 特别地, 有 \[ I(X;Y) = \lim_{n\to\infty} I(X_n,Y_n). \]
Pf (这里以一维随机向量为例) KL 散度的 \(\log\) 中 \(f\), \(g\) 作比, 把 \(n\) 消掉了: \[ \Align{ D(P_n,Q_n) &= \frac{1}{n} \sum_{i\in\Z} f(x_i) [\log{f(x_i)} - \log{g(y_i)}] \\ &\to D(f\parallel g). } \]
可见, KL 散度或者互信息这种相对的 (relative) 度量比熵这种绝对的度量更本质.
4.4 *Max entropy estimation
给出一个概率分布 PDF \(p(x)\) 的矩的信息, 比如 \[ \int_\R g_k(x)p(x)\dd{x} = r_k, \] (其中 \(g_k(x)=x^k\)) 如何估计 \(p(x)\)? 这当然是一个欠定问题. 我们加一个额外的条件, 即选择熵 / 微分熵最大的 \(p(x)\).
- 给定的条件可以减少 \(p\) 的不确定性. 而 \(p\) 的不确定性可以用熵衡量, 故 "最大熵解" 就是除了给定条件外, 不附加任何其他条件, 所得到的 \(p\).
将 max entropy estimation 形式化为条件极值问题 \[ \Align{ \min_{p\geq0} \pqty{\int_\R p(x)\ln{p(x)}\dd{x}}, \quad \textsf{s.t.}\; \Cases{ \int_\R p(x)\dd{x} = 1, \\ \int_\R g_k(x)p(x)\dd{x} = r_k,\textsf{for some}\;k\in\N^*. } } \] 我们使用 Lagrange 乘子法. 定义能量泛函 \[ J(p) := \int_\R p(x)\ln{p(x)}{\dd{x}} - \mu \pqty{\int_\R p(x){\dd{x}} - 1} - \sum_k\lambda_k \pqty{\int_\R g_k(x)p(x) {\dd{x}} - r_k}, \] 其极值点满足变分为零, 即 \[ 0 = \frac{\delta J}{\delta p} = \ln{p} + 1 - \mu - \sum_k \lambda_k g_k, \] 得到 \[ p(x) = \exp(\mu - 1)\cdot\exp(\sum_k\lambda_kg_k), \] 代入约束条件解出 \(\mu\) 和 \(\lambda_k\) 即可.
特别地, 对于 \(r_1=\mu\), \(r_2=\mu^2+\sigma^2\) 的情况 (即均值和方差分别为 \(\mu,\sigma^2\)), 可以解得 \[ p(x) = \frac1{\sqrt{2\pi}\sigma} \exp(-\frac{(x-\mu)^2}{2\sigma^2}) \] 恰恰是正态分布. 换言之, 正态分布是给定均值和方差后熵最大的分布.
该结论可以推广到 \(n\) 维.
Theorem 设 \(n\) 维随机向量 \(X\) 满足 \[ \operatorname{E}(X)=\mu,\qquad\operatorname{Cov}(X)=\Sigma, \] 则熵最大的满足条件的分布为 \(X\sim N(\mu,\Sigma)\).
Pf 由于微分熵关于平移不变, 不妨设 \(\mu=0\). 设 \(X\sim f(x)\) 服从 \(N(0,\Sigma)\), 任取分布 \(Y\sim g(x)\) 满足上述条件, 我们只需要证明 \(h(Y)\leq h(X)\). 一个技巧是计算 KL-散度 \[ \Align{ D(g\parallel f) &= \int_{\R^n} g(x) \ln\frac{g(x)}{f(x)} \dd{x} \\ &= \int_{\R^n} g(x)\ln{g(x)}\dd{x} - \int_{\R^n} g(x)\ln{f(x)}\dd{x} \\ &= -h(Y) - \biggl[ -\frac{n}{2}\ln(2\pi\det\Sigma) \underbrace{\int_{\R^n}g(x)\,{\dd{x}}}_{1} -\frac{1}{2} \underbrace{\int_{\R^n} (x\T\Sigma^{-1} x)g(x)\dd{x}} _{\operatorname{E}(Y\T\Sigma^{-1}Y)} \biggr]. } \] 仿照前文的方法可得 \(\operatorname{E}(Y\T\Sigma^{-1}Y)=n\), 于是 \[ D(g\parallel f) = -h(Y) - \biggl[ -\frac{n}{2}\ln(2\pi\det\Sigma) -\frac{n}{2} \biggr] = -h(Y) + h(X). \] 由 KL-散度的非负性, 有 \(h(Y)\leq h(X)\).